
Case Study #3: GA and Castells’ Network Society

Literature Review
As I noted in Case Study #2, Google Analytics (GA) appears most often in scholarship as a black-boxed application that reports (presumed accurate) visitor frequency and browsing behavior on websites. Websites are said by be “successful” in terms of reported visitor traffic to the site, number of pages viewed while on the site, length of browsing session, and additional metrics and dimensions. Few questions are asked of the application itself; its results are considered authoritative and accurate.
For this literature review, I sought scholarship that challenges the assumption of accuracy or convenience of GA data, either in term of collecting, configuring, processing, or reporting data. I also shifted my focus from searching in social sciences and humanities databases to searching in computer sciences-related databases. The results were mixed. On one hand, I found more scholarship that questioned Google Analytics and web/digital analytics in general; on the other hand, I found the scholarship less thorough than humanities or social sciences research.
Dhiman and Quach (2012) report briefly on the rationale and results of a workshop at CASCON ‘12 (Center for Advanced Studies on Collaborative Research) introducing Google’s Go and Dart, two applications under development (at the time) to enable “better analytics” and “better applications” (p. 253). The challenge Dhiman and Quach identify related to GA is that “in a world where there is an emergence of extensive use of analytics, data and fact-based decision making, spontaneous sorting of data becomes imperative…. [A]nalytics are crucial for knowledge discovery, business growth and technological improvements” (p. 253). Google Go is described as a “language that allows programmers to exploit concurrency in program by providing simple yet powerful features” that “make it an excellent language deploying application on concurrent systems” (p. 253). GA is one of many applications engaged in providing digital performance data; Go appears to provide programmers a language that enables concurrently-operating applications the ability to communicate with one another and to report on multiple application data at the same time. GA and other data-generating tools are implicitly critiqued for reporting data in a delayed and proprietary form that requires a mediating application to collate and report data spontaneously.
Fomitchev (2010) is far more direct in his GA critique. In a two-page poster presented at the 9th International Conference on World Wide Web, Fomitchev identifies specific inaccuracies in GA’s collecting of recurring website traffic using cookies. Specifically, Fomitchev finds that “Google Analytics ‘absolute unique visitor’ measure is shown to produce a similar 6x overestimation” of unique visitors (p. 1093). Based in comparative studies that collect recurrent visitor data via multiple methods, Fomitchev elaborates that “Google’s ‘absolute unique visitors’ are not at all unique: the inflation depends on the visitation frequency and grows linearly with time” (p. 1094, emphasis original). Given the potential, even likely, inflation of unique visitor numbers in GA reporting, Fomitchev concludes that the “discrepancy between unique cookies and unique visitors eases doubts in the accuracy of published unique visitor stats used to solicit advertising money” (p. 1094). While the critique of GA collecting methods is explicit, the implicit critique of using GA unique visitor reports to solicit funds for advertising seems more damning. GA as a free service must be monetized in Google ledgers, and advertising is where Google excels. If its reported data are inaccurate, its ethical foundation on accurate reporting (accuracy that is taken for granted, as shown in most studies) becomes suspect.
Back to the OoS
When I re-proposed Google Analytics as my object of study, I narrowed my discussion of GA to its data model and its activities. Both Dhiman and Quach (2012) and Fomitchev (2010) offer meaningful connections between GA and my theoretical lens, Castells’ (2010) social network theory. Dhiman and Quach reiterate the validity of Castells’ “space of flows” and “timeless time” in their needs assessment for a programming language that demonstrates “lightweight concurrency” in its ability to create sets of “lightweight communicating processes” between various programs running and reporting simultaneously (p. 254). Fomitchev (2010) corroborates Castells’ construction of “real virtuality” in which the local and the global function interchangeably and simultaneously, recognizing that GA, a global analytics application, is “fooled by periodic [local] cookie clearing and the multitude of [local] Internet access locations/devices…” (p. 1094).
Defining Google Analytics via Social Network Theory
Castells (2010) considers technology to be society (p. 5). While this seems extreme — I’d be more willing to accept technology as an aspect of society — the result is that GA can be considered social. As an information technology, GA creates active connections between websites (data collection), Google data centers (data configuring and processing) including aggregated tables (processing), and GA administrator accounts (configuring and reporting). These active connections collect, mediate (configure and process), and report on the three aspects of the GA data model consisting of users, sessions, and interactions. These connections represent social actions. So Castells (2010) might define GA as a global informational network (p. 77) that collects data from and reports data to local nodes (websites). Google servers where data are configured and processed might be consider mega-nodes (xxxviii) that, through the iterative process of increasing user visits and interaction by improving website design and content based on GA reported results, impose global logic on the local (xxxix).
Nodes in Google Analytics
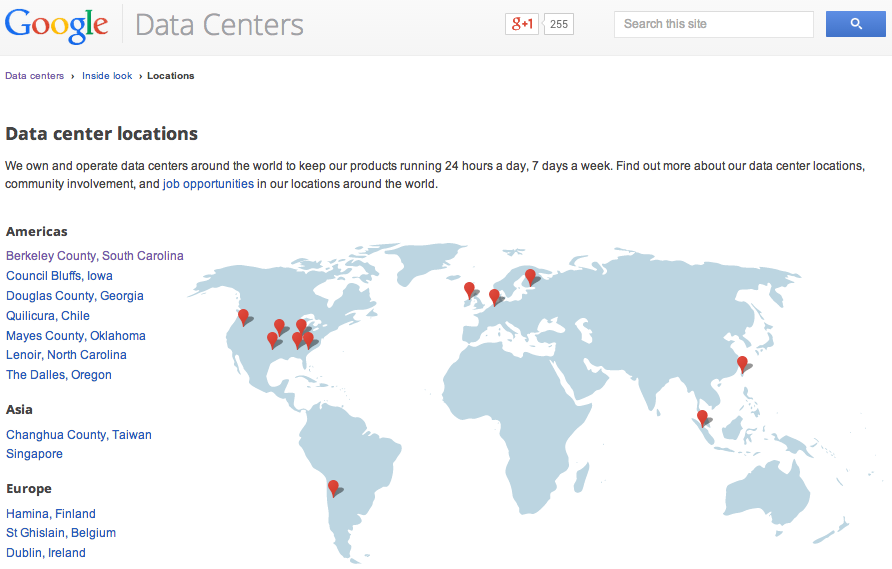
Google Data Center Locations: Image from Google Data Centers.
Individual websites, GA account administrators, and website visitors are local nodes in the global informational network. Google data center servers are mega-nodes in the network. Google employees who program GA and maintain Google servers and centers are localized nodes in the global network. Google’s data centers are located in a variety of locations that include North America, South America, Europe, and Asia. Several are found in Castells’ (2010) “milieux of innovation” (p. 419) including Taiwan, Singapore, and Chile. Others are found in what appear to be unlikely global spaces, including Council Bluffs, Iowa, and Mayes County, Oklahoma. These locations reiterate Castells’ insistence that local and global are not mutually exclusive polar opposites; rather, the new industrial system is neither global or local, but a new way of constructing local and global dynamics (p. 423). Websites, administrators, visitors, servers, and employees are simultaneously localized nodes (even the the mega-nodes are situated in space and time) in the global informational network.
Agency among Google Analytics Nodes
GA account administrators and website visitors have the greatest level of agency in the network, while Google employees exert limited agency within the confines of their labor relationships and conditions. Account administrators would likely be considered among Castells’ (2010) “managerial elites” (p. 445), while Google employees who maintain and program the servers might be part of Castells’ disposable labor force (p. 295). Account administrators have the authority to configure GA data, including the ability to filter out results, narrow data collection according to metrics and dimensions, and even integrate external digital metrics in GA. This authority is not, of course, the authority of Google’s corporate structure and hierarchy, but within the boundaries of GA data model and activities, account administrators exude authority. Website visitors may choose to visit, or not visit, any given website, once or more than once (meaning a single session or multiple sessions). This agency includes the power to intentionally separate themselves from the network, meaning that, for users, they only enter into the network as a node when they visit the tracked website. Interestingly, only the GA administrator has authority to eliminate users from the network; account configurations may filter out visitors along several dimensions.
Nodal Situation and Relation
Nodes are locally situated. While simultaneously part of the global informational economy, all of the nodes in the GA network are situated in a space and time. This simultaneous here/there compression of space and time is the origin of Castells’ (2010) “space of flows” (p. 408) and “timeless time” (p. 460). Websites are simultaneously hosted on physical servers around the world and locally viewed on specific platforms and media. Users are simultaneously accessing global data in territorial space on hardware. GA administrators are situated while configuring accounts and loading reports from the cloud. Google data centers are situated in specific locations, but they collect and process global data from local spaces and times. Google employees are culturally and territorially situated in the global Google labor pool.
Data rarely travels along parallel paths in the GA data model or GA activities. Website visit data are collected in the data model — user, session, and interaction data — and sent to Google data centers for processing and configuration. Other than writing unique user identification data onto cookies on users’ browsers or apps, little data travels from GA to users. Website content is indirectly affected by GA reports configured and read by GA administrators, but within the GA activity network, websites are unaffected by GA activity on the data model. Beyond the boundaries of the OoS, of course, Google serves plenty of data, in the form of ads, back to users. But that’s now beyond the scope of this study.
Movement in the Network

Framework for Movement: Wires in The Dalles, Oregon, Google Data Center. Photo from the Google Data Center Gallery.
Data moves in GA. More specifically, data in the GA data model moves in GA. Data are initiated by users visiting tracked websites. Specific frameworks must be in place for connections to occur and data in the data model to be collected. Namely, websites must contain GA tracking code, embedded in the website code through the agency of the GA administrator. The embedded GA tracking code enables, and the web browser and hardware afford (Norman, n.d.), the user to initiate a tracking pixel (gif) and generate data to be collected in the GA data model. Once collected, the data are configured (by the account administrator and by the GA algorithms), processed (in a largely opaque manner) and collated in aggregated data tables, and reported in visual and tabular representations. In Castells’ (2010) terms, data represent flow in the GA network (p. 442). That data is both spatial and temporal (it comes from and is attached to a specific territory and represents a specific, chronological activity), but it is also entirely global and digital.
Content in the Network
Data are collected and packaged — literally, in a gif image pixel — in parameters relating to user, session, and interaction. The GA tracking code encodes data and sends it to Google data centers where the data are decoded, configured based on administrator preferences, processed and repackaged in aggregated data tables, and made available to the account administrators. The reporting function remediates the data in visual and tabular formats for ease of reading and use. While the data reported are considered authoritative and authentic, the actual processing function remains largely proprietary, with only end results available to extrapolate what processing actually occurs. This black boxed processing function seems unlikely to represent Latour’s (2005) intermediary; as Fomitchev (2010) claims, there are probably processing functions that result in highly mediated, possibly even inaccurate, results. Castells (2010) would likely measure GA performance based on “its connectedness, that is, its structural ability to facilitate noise-free communication between its components” (p. 187). I hope we will see increased academic scrutiny focused on this perceived intermediary function in GA, even as we scholars rely on its results.
Birth and Death of a Network

Killing the Network: Failed Google data hard drives to be destroyed at the St. Ghislain, Belgium, Google Data Center. Photo from the Google Data Center Gallery.
Castells (2010) indicates that global informational networks emerge within milieux of innovation. These main centers of innovation are generally the largest metropolitan areas of the industrial age (p. 66), able to “generate synergy on the basis of knowledge and information, directly related to industrial production and commercial applications” (p. 67), and combine the efforts of the state and entrepreneurs (p. 69). Nodes on the network get ignored (and therefore cease to be part of the network) when they are perceived, by either the network or by its managerial elites, to have little value to the network itself (p. 134). The GA network grows as more nodes are added, either as users or as web pages with tracking code. GA administrators have agency to kill network nodes by removing tracking code from pages, or by directing IT managers to remove poorly performing web pages. Users have agency to quit visiting a website, thereby removing its value to the person. While many other actions by agents outside the GA network may affect the growth or dissolution of the network, they are outside the boundaries of the GA activity and data model.
Boundaries of Discussion
Two sets of boundaries apply. First, the boundaries I set in re-proposing my object of study, namely limiting the application of theory to GA’s activity and data model. By narrowing my object of study, I believe I’ve given myself the ability to tackle each aspect of the theory’s application to GA more specifically and directly. The result is greater clarity in describing GA function and in applying particular aspects of theory to the object.
Second, Castells sets some boundaries to the application. While Castells addresses the local, he tends to discuss localization in terms of groups rather than individuals. In this way, Castells more closely resembles ecological theories that apply to organism categories rather than to individual organisms. He regularly refers to groups of people and nodes: the managerial elites (rather than individual leaders), the technological revolution (rather than revolutionary technology pioneers), and the global and local economy (rather than the economic wellbeing of the individual small business owner). The result is that I can’t really address the individual user as a single agent in GA. Then again, this is hardly a hardship, in that GA aggregates data and anonymizes identities. GA, too, resembles an ecological theory rather than a rhetorical theory; it focuses on profiles of territorially localized users rather than individual users in a specific city. As a result, Castells and GA match rather nicely in defining the boundaries of the discussion. In fact, I’d argue that GA (and Google more broadly) represent precisely the network society Castells defined in his text. It’s interesting that he didn’t predict or recognize the rise of Google as I would have expected him to do in his 2010 preface. And Castells’ (2010) discussion of communication media clearly did not predict the popularity or ubiquity of Google’s YouTube on the network as a differentiated medium whose content is driven by user tastes and users-as-producers (p. 399).
Castells claims that his three-volume series did not try, and is not trying, to predict future evolution of the network. He also claims to avoid ethical judgments on the managerial elites’ treatment of those lacking connectivity in the global network. I found neither claim satisfactory. As GA “black boxes” processes that need to be problematized, so Castells “black boxes” prediction and judgment as processes without taking personal responsibility. In this way, too, Castells and GA are good matches.
References
Castells, M. (2010). The rise of the network society [2nd edition with a new preface]. Chichester, UK: Wiley-Blackwell.
Dhiman, K., & Quach, B. (2012). Google’s Go and Dart: Parallelism and structured web development for better analytics and applications. In Proceedings of the 2012 Conference of the Center for Advanced Studies on Collaborative Research, (pp. 253-254). Riverton, NJ: IBM Corporation.
Fomitchev, M. I. (2010, April 26). How Google Analytics and conventional cookie tracking techniques overestimate unique visitors [Poster]. In Proceedings of the 19th International Conference on World Wide Web, (pp. 1093-1094). New York, NY: Association for Computing Machinery.
Google Data Centers. (N.d.). Data center locations. Retrieved from http://www.google.com/about/datacenters/inside/locations/index.html
Latour, B. (2005). Reassembling the social: An introduction to actor-network-theory. Oxford, UK: Oxford University Press. Clarendon Lectures in Management Studies
Norman, D. (n.d.). Affordances and design. Don Norman Designs. Retrieved from http://www.jnd.org/dn.mss/affordances_and_desi.html